来源:llm/yi
在您的云上使用 SkyPilot 运行 Yi 模型#
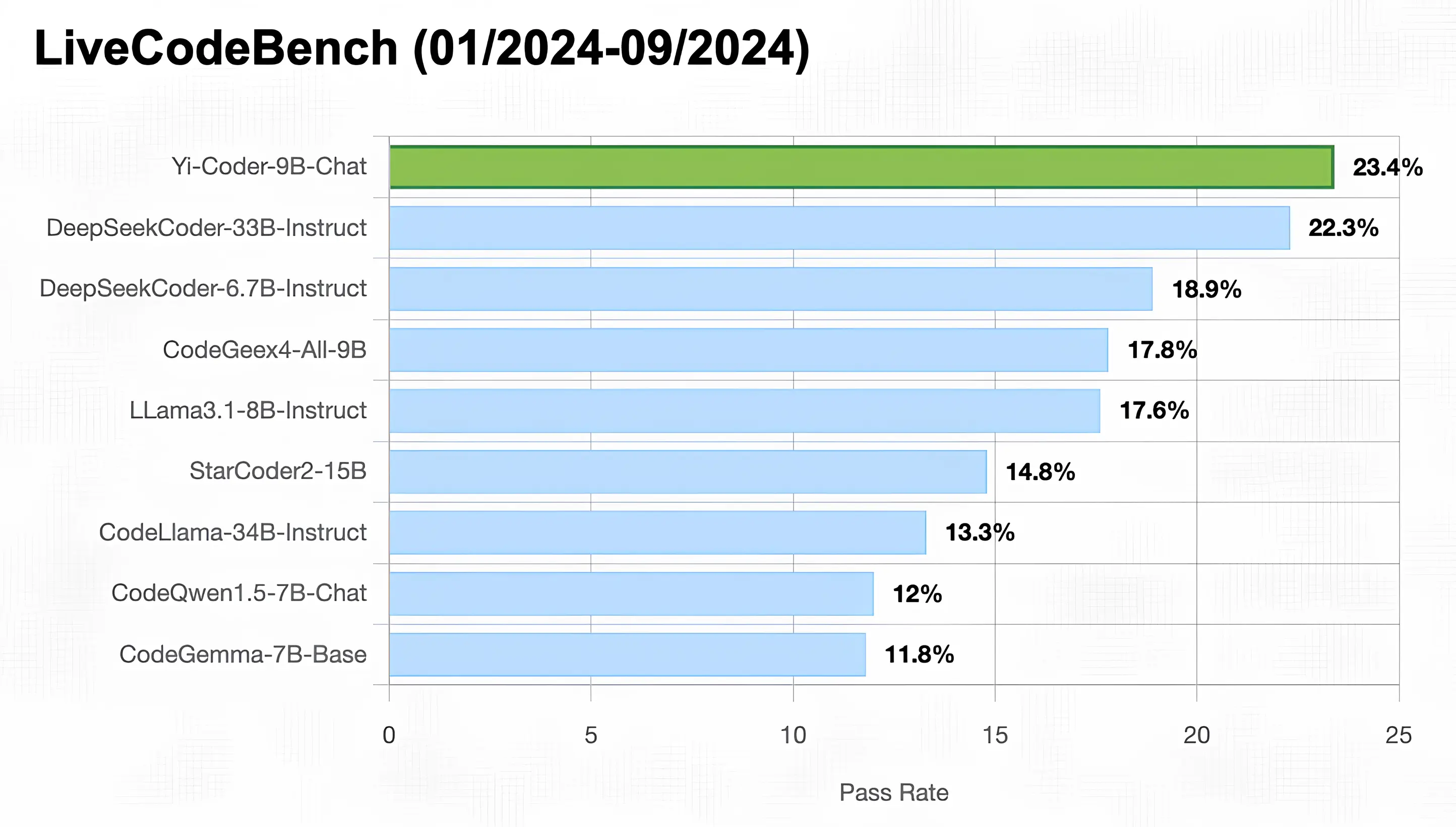
🤖 Yi 系列模型是 零一万物 (01.AI) 从头开始训练的新一代开源大型语言模型。
更新 (2024年9月19日) - SkyPilot 现已支持 Yi 模型 (Yi-Coder Yi-1.5)!
为什么使用 SkyPilot 部署而不是商业托管解决方案?#
通过利用 Kubernetes 集群和多个区域/云上的多个资源池,获得最佳的 GPU 可用性。
支付最低费用 — SkyPilot 会在 Kubernetes 集群和区域/云中选择最便宜的资源。没有托管解决方案的加价。
可在不同位置和加速器上扩展到多个副本,所有副本都通过单个端点提供服务。
所有内容都保留在您的 Kubernetes 或云账号中(您的虚拟机和存储桶)。
完全私有 - 没有其他人可以看到您的聊天记录。
使用 SkyPilot 运行 Yi 模型#
安装 SkyPilot 后,一键即可使用 SkyPilot 在 vLLM 上运行您自己的 Yi 模型。
通过 vLLM 提供支持的 OpenAI 兼容端点,在单个实例上启动 Yi-1.5 34B 模型服务,可使用 yi15-34b.yaml 中指定的列表中的任何可用 GPU(您也可以切换到 yicoder-9b.yaml 或 其他模型 以使用较小的模型)。
sky launch -c yi yi15-34b.yaml
向端点发送补全请求
ENDPOINT=$(sky status --endpoint 8000 yi)
curl http://$ENDPOINT/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "01-ai/Yi-1.5-34B-Chat",
"prompt": "Who are you?",
"max_tokens": 512
}' | jq -r '.choices[0].text'
发送聊天补全请求
curl http://$ENDPOINT/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "01-ai/Yi-1.5-34B-Chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Who are you?"
}
],
"max_tokens": 512
}' | jq -r '.choices[0].message.content'
包含的文件#
yi15-34b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-34B-Chat
resources:
accelerators: {A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_size: 1024
disk_tier: best
memory: 32+
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yi15-6b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-6B-Chat
resources:
accelerators: {L4, A10g, A10, L40, A40, A100, A100-80GB}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yi15-9b.yaml
envs:
MODEL_NAME: 01-ai/Yi-1.5-9B-Chat
resources:
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yicoder-1_5b.yaml
envs:
MODEL_NAME: 01-ai/Yi-Coder-1.5B-Chat
resources:
accelerators: {L4, A10g, A10, L40, A40, A100, A100-80GB}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log
yicoder-9b.yaml
envs:
MODEL_NAME: 01-ai/Yi-Coder-9B-Chat
resources:
accelerators: {L4:8, A10g:8, A10:8, A100:4, A100:8, A100-80GB:2, A100-80GB:4, A100-80GB:8}
disk_tier: best
ports: 8000
setup: |
pip install vllm==0.6.1.post2
pip install vllm-flash-attn
run: |
export PATH=$PATH:/sbin
vllm serve $MODEL_NAME \
--host 0.0.0.0 \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--max-model-len 1024 | tee ~/openai_api_server.log