概述#
SkyPilot 将您的云基础设施 — Kubernetes 集群、云和虚拟机区域以及现有机器 — 组合成一个统一的计算资源池,该资源池针对运行 AI 工作负载进行了优化。
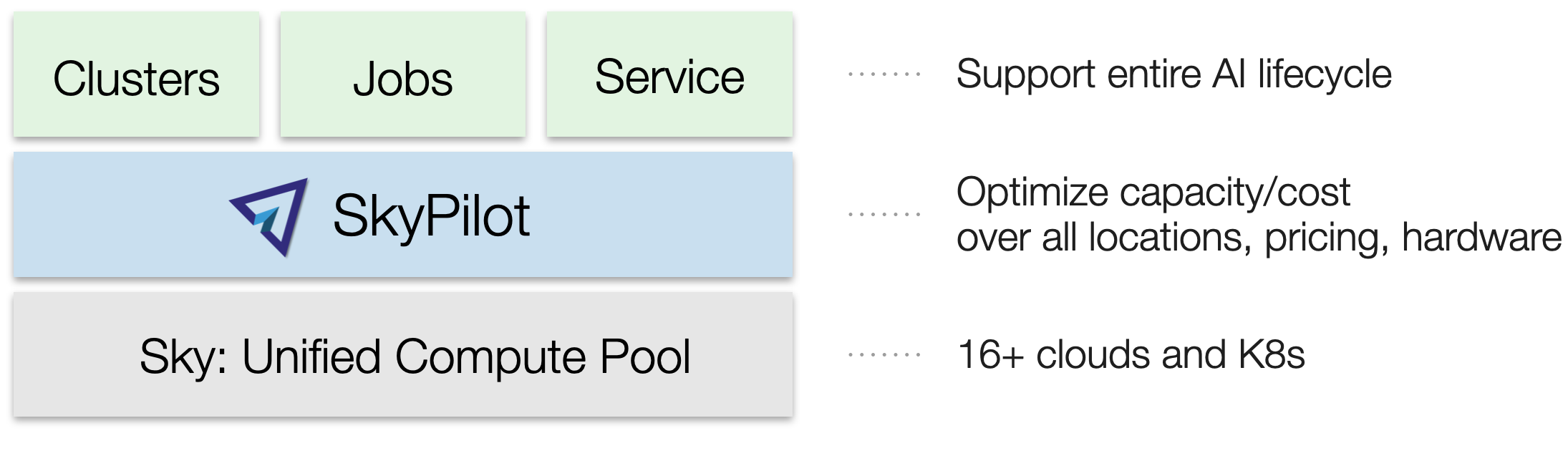
您可以使用这些核心抽象,在统一的界面中,在此资源池上运行 AI 工作负载
集群
作业
服务
这些抽象支持 AI 生命周期的所有用例:批量处理、开发、(预)训练、微调、超参数搜索、批量推理和在线服务。
使用 SkyPilot 运行工作负载具有以下优势
在任何云、区域和集群上的统一执行
无论您拥有多少云、区域和集群,您都可以使用统一的界面在它们上面提交、运行和管理工作负载。
您专注于工作负载,SkyPilot 减轻了处理云基础设施细节和差异的负担。
成本和容量优化
启动工作负载时,SkyPilot 将自动选择您的搜索空间中最便宜且最可用的基础设施选项。
跨基础设施选项自动故障转移
启动工作负载时,您可以为 SkyPilot 提供一个基础设施选项的搜索空间 — 您可以根据需要设置限制或具体。
如果某个基础设施选项没有容量,SkyPilot 会自动回退到您的基础设施搜索空间中的下一个最佳选项。
无云供应商锁定
如果您将来添加基础设施选项(例如,新的云、区域或集群),您的现有工作负载可以轻松地在它们上面运行。无需复杂的迁移或工作流更改。请参阅底层的 天空计算 愿景。
集群#
一个 集群 是 SkyPilot 的核心资源单元:位于同一位置的一个或多个虚拟机或 Kubernetes Pod。
您可以使用 sky launch 启动一个集群
$ sky launch
$ sky launch --gpus L4:8
$ sky launch --num-nodes 10 --cpus 32+
$ sky launch --down cluster.yaml
$ sky launch --help # See all flags.
import sky
task = sky.Task().set_resources(sky.Resources(accelerators='L4:8'))
sky.launch(task, cluster_name='my-cluster')
您可以使用集群进行以下操作
SSH 连接到任何节点
将 VSCode/IDE 连接到它
在其上提交和排队多个作业
使其自动关闭或停止以节省成本
轻松启动和使用多个虚拟的、临时的集群
或者,您可以在启动时带上自定义的 Docker 或虚拟机镜像,或者使用 SkyPilot 的合理默认设置,这些设置会为不同的 GPU 配置正确的 CUDA 版本。
请注意,SkyPilot 集群是云实例的 虚拟 集合,或者是您带入 SkyPilot 的 物理 集群(Kubernetes 集群 或 现有机器)上启动的 Pod 的虚拟集合。
作业#
一个 作业 是您想要运行的程序。支持两种类型的作业
集群上的作业 |
托管作业 |
|---|---|
用法: |
用法: |
作业提交到现有集群并重用该集群的设置。 |
每个作业都在自己的临时集群中运行,并带有自动恢复功能。 |
非常适合在现有集群上进行交互式开发和调试。 |
非常适合需要恢复(例如,Spot 实例)或扩展到许多并行作业的作业。 |
一个作业可以包含一个或 多个 任务。在大多数情况下,一个作业只有一个任务;我们将它们交替使用。
集群上的作业#
您可以使用 sky exec 在现有集群上排队和运行作业。这非常适合交互式开发,重用集群的设置。
请参阅 集群作业 以开始使用。
sky exec my-cluster --gpus L4:1 --workdir=. -- python train.py
sky exec my-cluster train.yaml # Specify everything in a YAML.
# Fractional GPUs are also supported.
sky exec my-cluster --gpus L4:0.5 -- python eval.py
# Multi-node jobs are also supported.
sky exec my-cluster --num-nodes 2 -- hostname
# Assume you have 'my-cluster' already launched.
# Queue a job requesting 1 GPU.
train = sky.Task(run='python train.py').set_resources(
sky.Resources(accelerators='L4:1'))
train = sky.Task.from_yaml('train.yaml') # Or load from a YAML.
sky.exec(train, cluster_name='my-cluster')
# Queue a job requesting 0.5 GPU.
eval = sky.Task(run='python eval.py').set_resources(
sky.Resources(accelerators='L4:0.5'))
sky.exec(eval, cluster_name='my-cluster')
托管作业#
托管作业 会自动为每个作业调配一个临时集群并处理自动恢复。使用轻量级作业控制器提供无需手动干预的监控和恢复。您可以使用 sky jobs launch 启动托管作业。
托管作业特别适合在可抢占的 Spot 实例上运行作业(例如,微调、批量推理)。Spot GPU 通常可以节省 3-6 倍的成本。它们也非常适合扩展到许多并行作业。
建议模式:先使用集群进行交互式开发和调试代码,然后使用托管作业大规模运行它们。
服务#
一个 服务 用于 AI 模型服务。一个服务可以有一个或多个副本,可能跨越不同的位置(区域、云、集群)、定价模型(按需、Spot 等),甚至 GPU 类型。
请参阅 模型服务 以开始使用。
接入您的基础设施#
SkyPilot 使用每种基础设施的原生认证(云凭据、kubeconfig、SSH)轻松连接到您现有的基础设施——云、Kubernetes 集群或本地机器。
云虚拟机#
SkyPilot 可以在您有权访问的云和区域上启动虚拟机。运行 sky check 检查访问权限。
SkyPilot 支持大多数主要的云提供商。有关详细信息,请参阅 设置 Kubernetes 或云。


默认情况下,SkyPilot 重用您现有的云认证方法。或者,您也可以 设置 SkyPilot 使用的特定角色、权限或服务账户。
Kubernetes 集群#
您可以将现有的 Kubernetes 集群,包括托管集群(例如 EKS、GKE、AKS)或本地集群,接入 SkyPilot。也支持多个集群之间的自动故障转移。
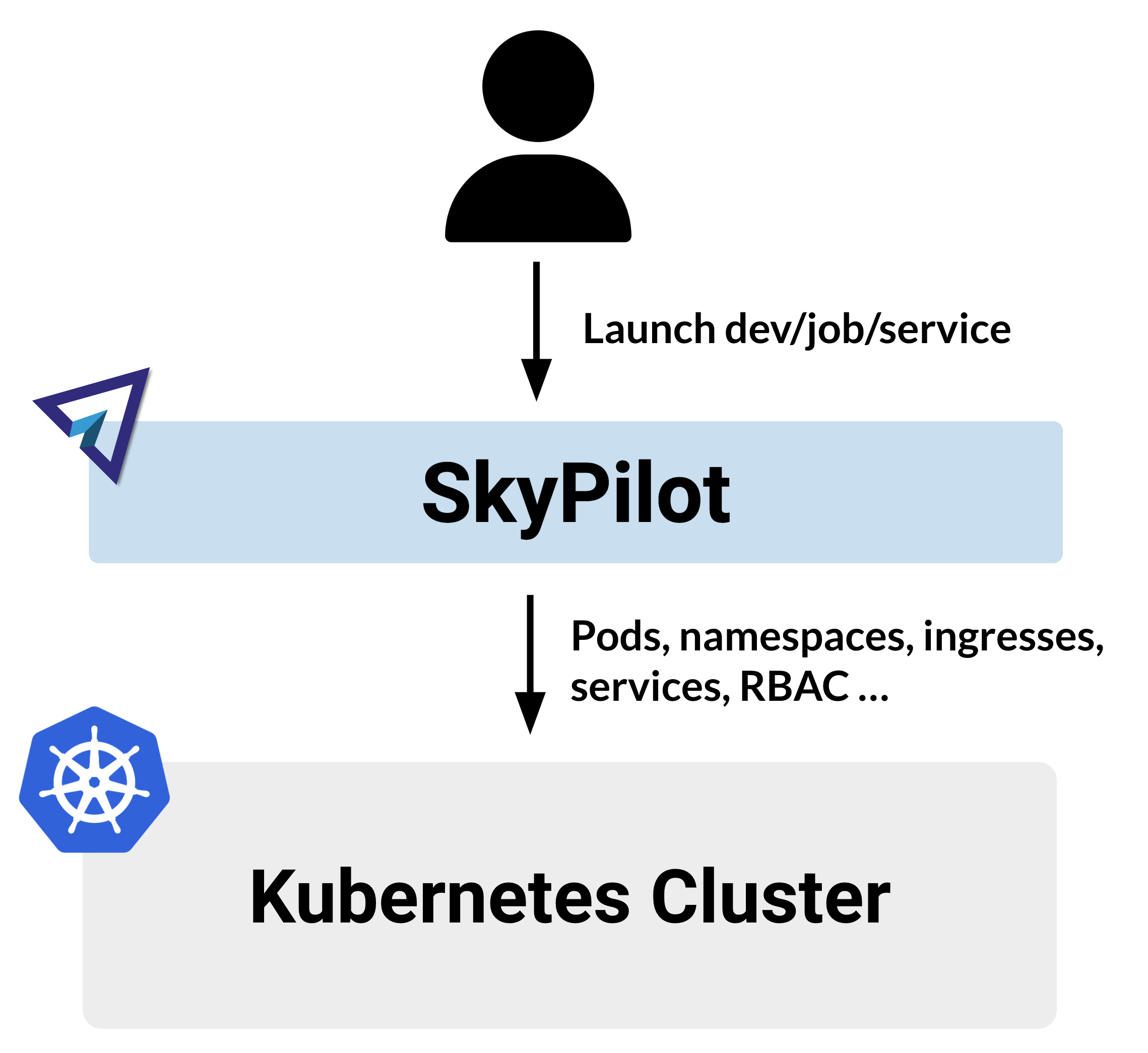
请参阅 使用 Kubernetes。
现有机器#
如果您有现有机器,即一个可以通过 SSH 连接的 IP 地址列表,您可以将它们接入 SkyPilot。
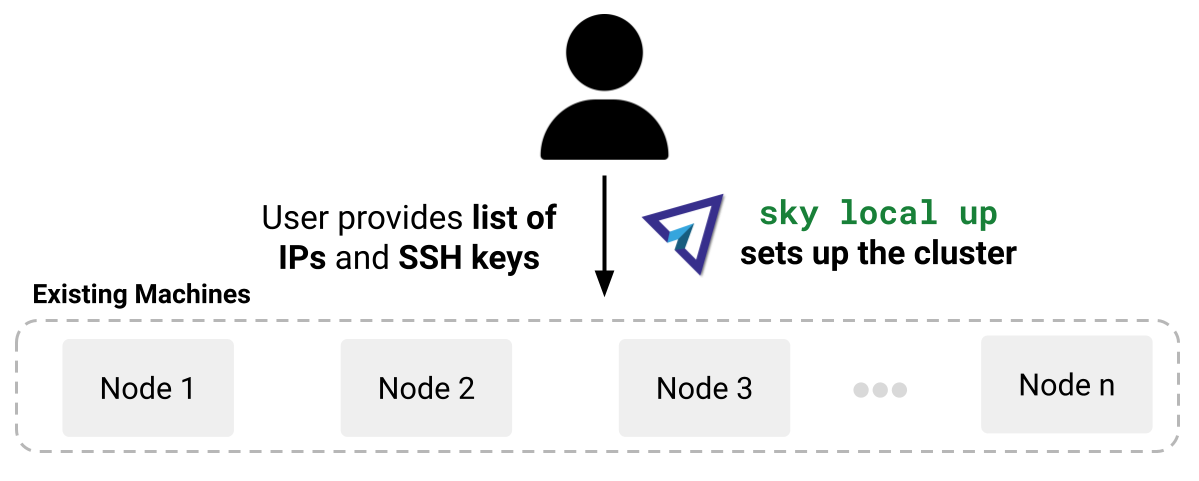
请参阅 使用现有机器。
SkyPilot 的成本和容量优化#
每当集群、作业或服务需要新的计算资源时,SkyPilot 的资源调配器会原生优化成本和容量,选择最便宜且可用的基础设施选项。
例如,如果您想启动一个带有 8 个 A100 GPU 的集群,SkyPilot 将按照“最便宜且可用”的顺序尝试给定搜索空间中的所有基础设施选项,并带有自动故障转移功能
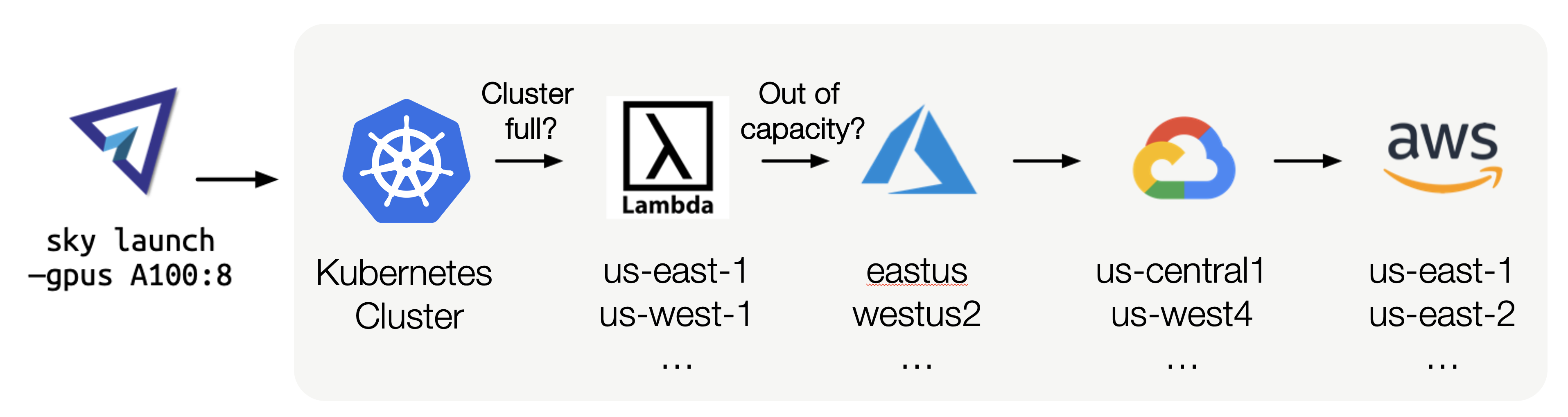
因此,SkyPilot 用户不再需要担心特定的基础设施细节、手动重试或手动设置。工作负载也能获得更高的 GPU 容量和成本节约。
用户可以指定每个工作负载的搜索空间。它可以根据需要灵活或具体。可以指定的示例搜索空间
使用集合中最便宜且可用的 GPU,
{A10g:8, A10:8, L4:8, A100:8}使用我的 Kubernetes 集群或任何可访问的云(如上图所示)
使用 Spot 或按需的 H100 GPU
只使用 AWS 的五个欧洲区域
使用特定的可用区、区域或云
优化是在搜索空间内执行的。有关详细信息,请参阅 资源调配计算。
在本地使用 SkyPilot 或为团队部署#
SkyPilot 可以在本地使用,也可以作为集中式 API 服务器为您的团队部署。
团队部署使您能够跨多个用户共享和管理计算资源
一次部署,随处使用:在 Kubernetes 或云虚拟机上部署 SkyPilot API 服务器,并在任何地方访问它。
团队资源共享:团队成员可以相互共享资源。
新成员轻松上手:用户无需设置本地云凭据即可运行 SkyPilot 命令。
全局视图和控制:管理员可以获得整个团队计算资源(跨集群和区域)的单一视图。
有关详细信息,请参阅 团队部署。