SkyPilot 对比原生 Kubernetes#
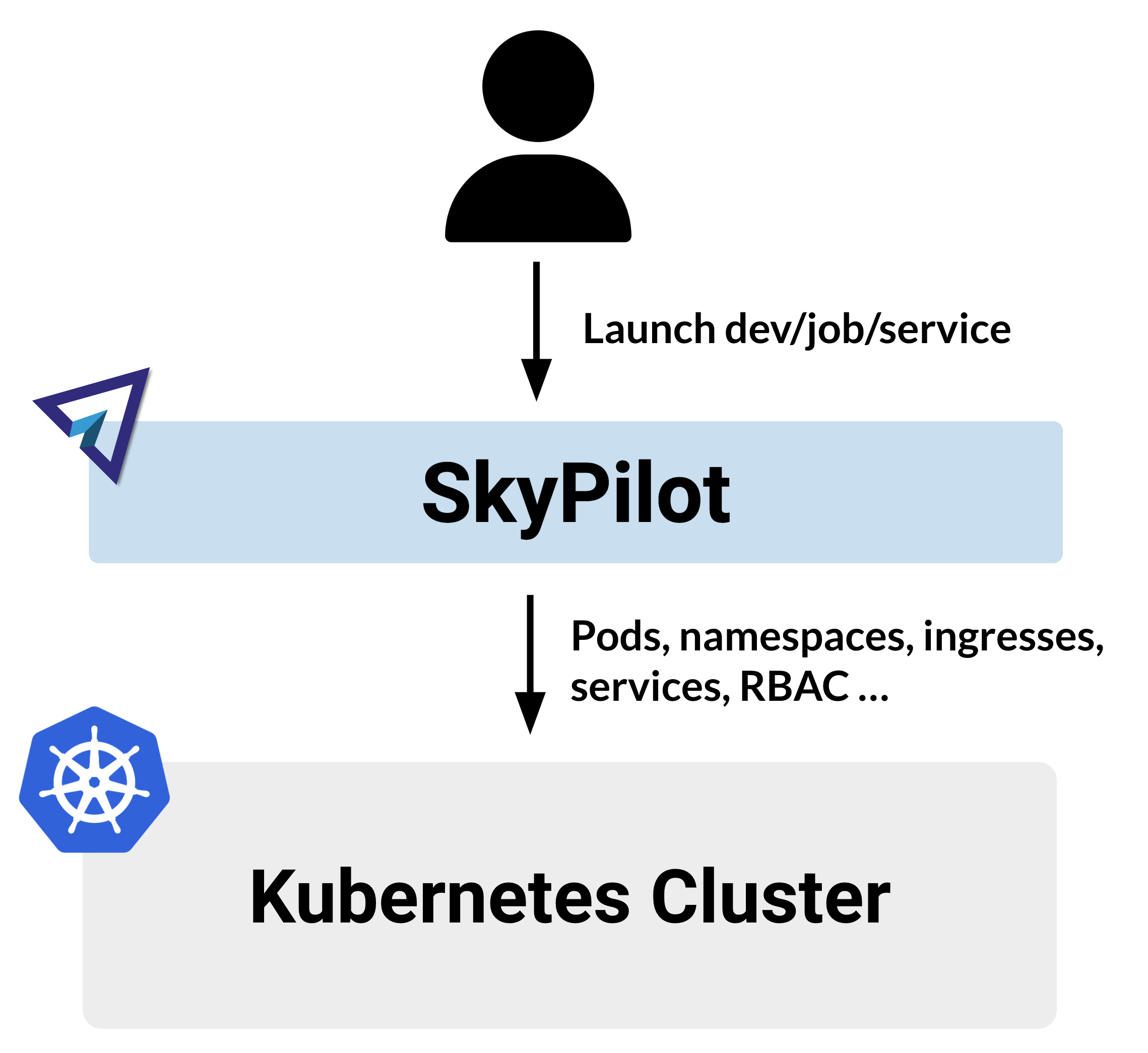
Kubernetes 是一个用于管理容器化应用程序的强大系统。使用 SkyPilot 访问您的 Kubernetes 集群可以提高开发人员的生产力,并允许您将基础设施扩展到单个 Kubernetes 集群之外。
SkyPilot 在您的 Kubernetes 集群之上构建,以提供更好的开发者体验。#
SkyPilot 在您的 Kubernetes 集群之上构建,以提供更好的开发者体验。#
更快的开发者迭代速度#
SkyPilot 为交互式开发提供了更快的迭代速度。例如,AI 工程师的一个常见工作流程是通过调整代码和超参数并观察训练运行来迭代地开发和训练模型。
使用 Kubernetes,单次迭代是一个多步骤过程,包括构建 Docker 镜像、将其推送到注册表、更新 Kubernetes YAML,然后进行部署。
使用 SkyPilot,一个简单的命令(
sky launch)即可处理一切。在幕后,SkyPilot 会配置 Pod、安装所有必需的依赖项、执行作业、返回日志,并提供 SSH 和 VSCode 访问以便调试。

使用 Kubernetes 进行迭代开发需要繁琐地更新 Docker 镜像和多个步骤来更新训练运行。使用 SkyPilot,您只需要一个 CLI 命令(sky launch)。#
更简单的 YAML 配置#
考虑在 Kubernetes 上使用 vLLM 提供 Gemma 服务
使用原生 Kubernetes,您需要超过 65 行 Kubernetes YAML 来启动使用 vLLM 提供服务的 Gemma 模型。
使用 SkyPilot,只需一个易于理解的 19 行 YAML 即可启动使用 vLLM 提供 Gemma 服务的 Pod。
以下是 SkyPilot 和 Kubernetes 上使用 vLLM 提供 Gemma 服务的 YAML 对比
SkyPilot(19 行)
1envs:
2 MODEL_NAME: google/gemma-2b-it
3 HF_TOKEN: myhftoken
4
5resources:
6 image_id: docker:vllm/vllm-openai:latest
7 accelerators: L4:1
8 ports: 8000
9
10setup: |
11 conda deactivate
12 python3 -c "import huggingface_hub; huggingface_hub.login('${HF_TOKEN}')"
13
14run: |
15 conda deactivate
16 echo 'Starting vllm openai api server...'
17 python -m vllm.entrypoints.openai.api_server \
18 --model $MODEL_NAME --tokenizer hf-internal-testing/llama-tokenizer \
19 --host 0.0.0.0
Kubernetes(65 行)
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: vllm-gemma-deployment
5spec:
6 replicas: 1
7 selector:
8 matchLabels:
9 app: gemma-server
10 template:
11 metadata:
12 labels:
13 app: gemma-server
14 ai.gke.io/model: gemma-1.1-2b-it
15 ai.gke.io/inference-server: vllm
16 examples.ai.gke.io/source: user-guide
17 spec:
18 containers:
19 - name: inference-server
20 image: us-docker.pkg.dev/vertex-ai/ vertex-vision-model-garden-dockers/pytorch-vllm-serve:20240527_0916_RC00
21 resources:
22 requests:
23 cpu: "2"
24 memory: "10Gi"
25 ephemeral-storage: "10Gi"
26 nvidia.com/gpu: 1
27 limits:
28 cpu: "2"
29 memory: "10Gi"
30 ephemeral-storage: "10Gi"
31 nvidia.com/gpu: 1
32 command: ["python3", "-m", "vllm.entrypoints.api_server"]
33 args:
34 - --model=$(MODEL_ID)
35 - --tensor-parallel-size=1
36 env:
37 - name: MODEL_ID
38 value: google/gemma-1.1-2b-it
39 - name: HUGGING_FACE_HUB_TOKEN
40 valueFrom:
41 secretKeyRef:
42 name: hf-secret
43 key: hf_api_token
44 volumeMounts:
45 - mountPath: /dev/shm
46 name: dshm
47 volumes:
48 - name: dshm
49 emptyDir:
50 medium: Memory
51 nodeSelector:
52 cloud.google.com/gke-accelerator: nvidia-l4
53---
54apiVersion: v1
55kind: Service
56metadata:
57 name: llm-service
58spec:
59 selector:
60 app: gemma-server
61 type: ClusterIP
62 ports:
63 - protocol: TCP
64 port: 8000
65 targetPort: 8000
扩展到单个区域/集群之外#
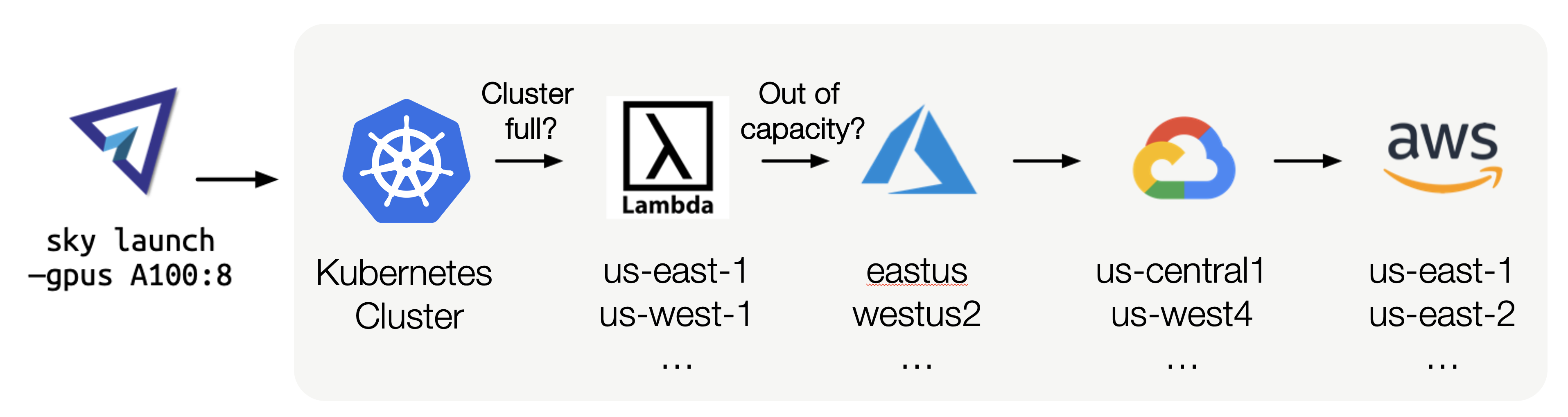
如果 Kubernetes 集群已满,SkyPilot 可以从其他区域和云获取 GPU,以最低成本运行您的任务。#
Kubernetes 集群通常受限于单个云中的单个区域。这是因为 etcd 作为 Kubernetes 状态的控制存储,在面对跨区域较高延迟时可能会超时并失败 [1] [2] [3]。
使用原生 Kubernetes 受限于单个区域/云有两个缺点
1. GPU 可用性降低,因为您无法利用其他地方的可用容量。
2. 成本增加,因为您无法利用其他区域更便宜的资源。
SkyPilot 旨在跨云和跨区域扩展:它允许您在 Kubernetes 集群上运行任务,并在需要时爆发到更多区域和云。这样做,SkyPilot 确保您的任务始终在最具成本效益的区域运行,同时保持高可用性。